
My Node.js is a bit Rusty
This blog post has been residing in "draft" mode for quite a while now. I've finally decided to just publish it. As such, a few things might be a bit off, but... that's life, isn't it? I'm eager to hear what you think.
Back in 2020, my team at Wix launched a new internal product called CDN Stats. As the name suggests, CDN Stats is a platform that displays and aggregates data and statistics derived from Wix's CDN.
That same year, I delivered a presentation about an experiment I conducted. This experiment, which involved rewriting a single module into a native Node.js add-on using Rust, resulted in a staggering 25x performance improvement.
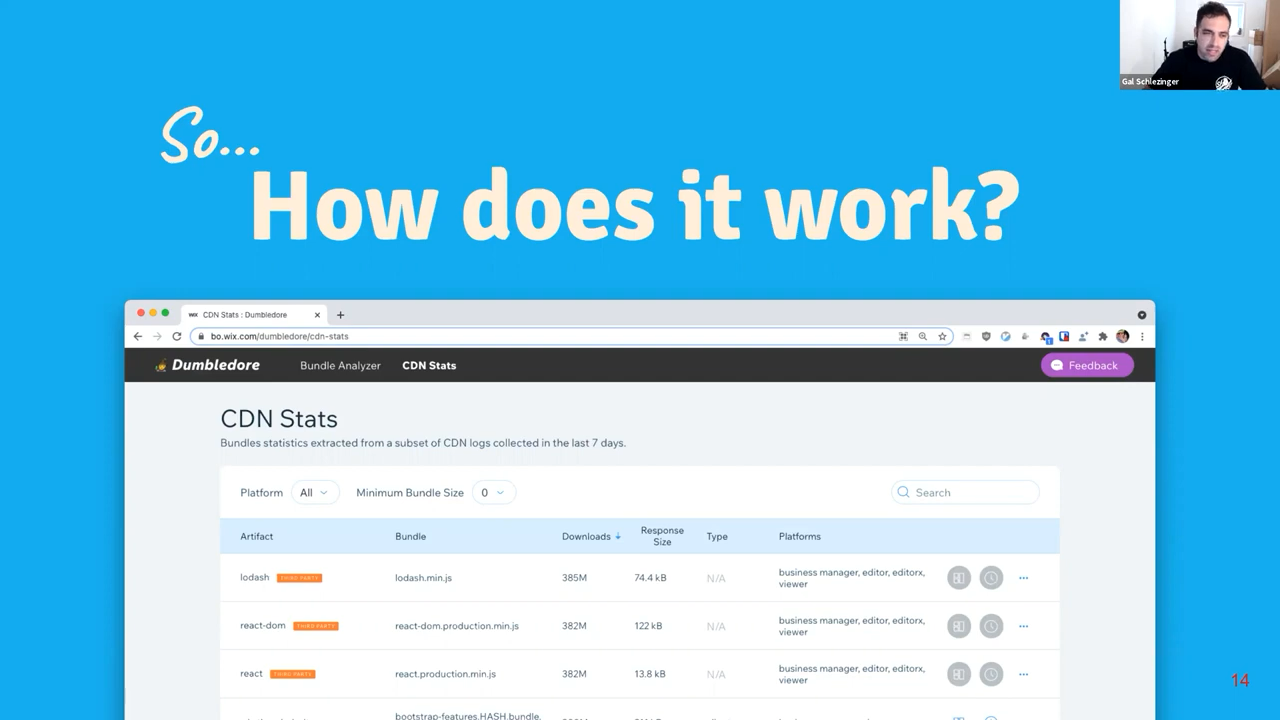 CDN stats screenshot from the talk.
CDN stats screenshot from the talk.
This platform empowers front-end developers at Wix by providing real-time data on the usage of their compiled assets by our customers, including:
- Platforms
- Downloads (per platform)
- Response size (transfer size)
These metrics allow front-end developers to identify which bundles need optimization and the urgency of these optimizations. It helped us rectify a critical issue that we might have otherwise overlooked: due to a human error, one of our primary JavaScript assets ballooned to 33MB(!) because it inlined uncompressed SVG without externalizing it or even dynamically importing it.
This project seems fairly straightforward, doesn't it? All we're doing is counting and summing up some values! Toss in some indices in the database, present it with a data table, and voila. But is it really that simple?
How does that work?
In order to populate the data table, we need to sift through the CDN logs. These are tab-separated values files (TSV) stored in Amazon S3. We're talking about ~290k files per day, which can amount to 200GB.
So, every day, we download the TSV files from the previous day, parse them into meaningful information, and store this data in our database. We accomplish this by enqueuing each log file into a job queue. This strategy allows us to parallelize the process and utilize 25 instances to parse the log files within approximately 3 hours each day.
Then, every few hours, we generate an aggregation for the previous week. This process takes around ~1 hour and is primarily executed in the database using a MongoDB aggregation.
The MongoDB query was pretty intense.
You may be thinking, "Isn't that a problem AWS Athena can solve?" and you'd be absolutely right. However, let's set that aside for now. It simply wasn't an option we were able to utilize at the time.
So What's the Problem?
Parsing gigabytes of TSV files might seem like a tedious task. Investing so much time and resources on it... well, it's not exactly a joy. To be brutally honest: having 25 Node.js instances running for three hours to parse 200GB of data seems like an indication that something isn't quite right.
The solution that eventually worked was not our first attempt. Initially, we tried using the internal Wix Serverless framework. We processed all log files concurrently (and aggregated them using Promise.all, isn't that delightful?). However, to our surprise, we soon ran into out-of-memory issues, even when using utilities like p-limit to limit ourselves to just two jobs in parallel. So, it was back to the drawing board for us.
Our second approach involved migrating the same code, verbatim, to the Wix Node.js platform, which runs on Docker containers in a Kubernetes cluster. We still encountered out-of-memory issues, leading us to reduce the number of files processed in parallel. Eventually, we got it to work—however, it was disappointingly slow. Processing a single day's worth of data took more than a day. Clearly, this was not a scalable solution!
So, we decided to try the job queue pattern. By scaling our servers to 25 containers, we managed to achieve a more reasonable processing time. But, can we truly consider running 25 instances to be reasonable?
Perhaps it's time to consider that JavaScript may be the problem. There might be certain issues that JavaScript simply can't solve efficiently, especially when the work is primarily CPU and memory bound—areas where Node.js doesn't excel.
But why is that so?
Node.js is a Garbage Collected VM
Node.js is a remarkable piece of technology. It fosters innovation and enables countless developers to accomplish tasks and deliver products. Unlike languages such as C and C++, JavaScript does not require explicit memory management. Everything is handled by the runtime—in this case, a VM known as V8.
V8 determines when to free up memory. This is how many languages are designed to optimize the developer experience. However, for certain applications, explicit memory usage is unavoidable.
Let's analyze what (approximately) transpires when we execute our simplified TSV parsing code:
for await (const line of readlineStream) {
const fields = line.split("\t");
const httpStatus = Number(fields[5]);
if (httpStatus < 200 || httpStatus > 299) continue;
records.push({
pathname: fields[7],
referrer: fields[8],
// ...
});
}
This code is quite straightforward. By using readline, we iterate through lines in the file in a stream to circumvent memory bottlenecks caused by reading the entire file into memory. For every line, we split it by the tab character and push an item to an array of results. But what's happening behind the scenes in terms of memory?
When line.split('\t') is invoked, we get a newly allocated array containing multiple items. Each item is a newly allocated string that occupies memory. This is the way Array\#split works: it creates a new array and strings every time.
The intriguing part here is that line and fields won't be cleared from memory until the garbage collector determines it's time to do so. We find ourselves with RAM filled with redundant strings and arrays that need cleaning. It's hardly surprising that our computer wasn't thrilled with this situation.
Finding Comfort in Rust
As an intermediate Rustacean (I do have a fairly successful open-source project written in Rust, called fnm), I'm well aware that memory management is one of Rust's key strengths. The fact that Rust does not require a runtime garbage collector makes it suitable for embedding within other languages and virtual machines, positioning it as an ideal candidate for implementing such features.
I've shared a few tweets expressing my beliefs. Building applications in Rust is powerful, but the ability to embed Rust in a battle-tested VM without altering the rest of your application is a true game-changer. Creating a service in Node.js and only using Rust when necessary can help you accelerate development and replace modules with more efficient ones as and when required.
Using Node.js as the entry point of our application enabled me to leverage Wix’s standard storage/database connectors, error reporting and logging, and configuration management, without the need to re-implement these on the Rust side. This allowed me to focus solely on what mattered most: optimizing the slow part.
Fortunately, embedding Rust in Node.js is a breeze, thanks to https://napi.rs: an excellent Rust library that facilitates seamless integration between Rust and Node.js. You simply write a Rust library, use some fancy macros, and voila! You have a native Node.js module written in Rust.
The Rust code
In Rust, I can begin by declaring my structs as the relevant data structures I want to parse the lines into—a "type-driven development" workflow. I started with Record, the most basic line I want to parse from a TSV record set. Instead of designating every part of the Record as String (an owned string), I can force it to be a reference, &'a str, which lives for the lifetime of 'a:
struct Record<'a> {
pathname: &'a str,
referrer: &'a str,
// ...
}
By making Record contain slices of strings (with a 'a lifetime), we're essentially stating that Record is a derived data structure that doesn't alter the original data. This implies that Record cannot outlive line—an advantageous feature. It aids us in developing our application while being mindful of optimal memory usage.
So, what exactly is Record? It's a struct that organizes the raw data in a structured manner. However, merely deriving the raw data isn't sufficient for our use case. To maximize the capabilities of browser caching, static assets are deployed with a content hash as part of the filename. Instead of having a /artifact/file.js, we have /artifact/file.abcdef0123456.js files, allowing the browser to cache them indefinitely.
For our aggregations, we want to remove this content hash. Furthermore, we want to infer the artifact name from the pathname. This is why we introduced EnhancedRow:
struct EnhancedRow<'a> {
pathname: &'a str,
referrer: &'a str,
// ...
artifact: &'a str, // This is a slice of pathname
// => a slice of a slice => a slice
filename: Cow<'a, str>,
// ...
}
As we can see, EnhancedRow<'a> incorporates everything that Record<'a> does, but it enhances it with a few values:
artifactis a&'a str, as it refers to a part of thepathnameslice. No cloning is necessary to obtain this information.filenameis aCow<'a, str>, or "copy on write". As we just mentioned, we attempt to remove the content hash from the file. If we don't find a content hash, there's no need to copy the string. If we do find it, we copy the string. This type allows us to be incredibly explicit about our intentions.
After defining these two structs, we implemented TryFrom<&'a str> for Record<'a> and TryFrom<Record<'a>> for EnhancedRecord<'a>, enabling us to safely parse a borrowed string into a Record, and then into an EnhancedRecord, with minimal cloning involved.
Next, we created a new struct called ResourceCounter, which performed the aggregation for the given files. It was a simple wrapper around HashMap. Our key was composed of (artifact, file_name), and our value had a counter for requests, based on Platforms.
ResourceCounter allows us to provide an EnhancedRecord<'a>, and it only clones data if necessary. So, if the artifact/filename had never been encountered before, it would clone the data.
With this, our code was complete. However, since we were implementing a performance optimization feature, we knew we couldn't call it a day without benchmarking it against the current JavaScript implementation. This benchmarking would require us to use the Node.js module (rather than using Rust as a CLI or similar) to ensure we included the overhead of the JS and Rust communication.
I fired up our internal JavaScript benchmarking tool (called Perfer) and wrote a simple benchmark:
import { benchmark } from "@wix/perfer";
import * as jsParser from "@wix/cdn-stats-js-parser";
import * as nativeParser from "@wix/cdn-stats-native-parser";
import fs from "fs";
import assert from "assert";
benchmark.node("native parser", async () => {
const values = await nativeParser.runAsync(["../SOME_BIG_FIXTURE"]);
assert.ok(values.length > 0);
});
benchmark.node("js parser", async () => {
const stream = fs.createReadStream("../SOME_BIG_FIXTURE");
const values = await jsParser.runAsync([stream]);
assert.ok(values.length > 0);
});
and ran it. The results were impressive:
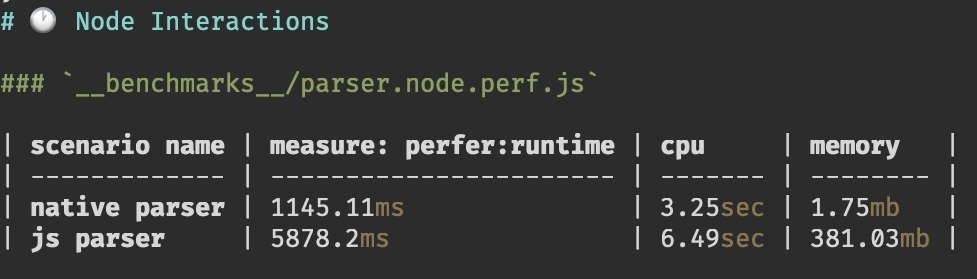 A screenshot from the CLI output of the benchmarking tool
A screenshot from the CLI output of the benchmarking tool
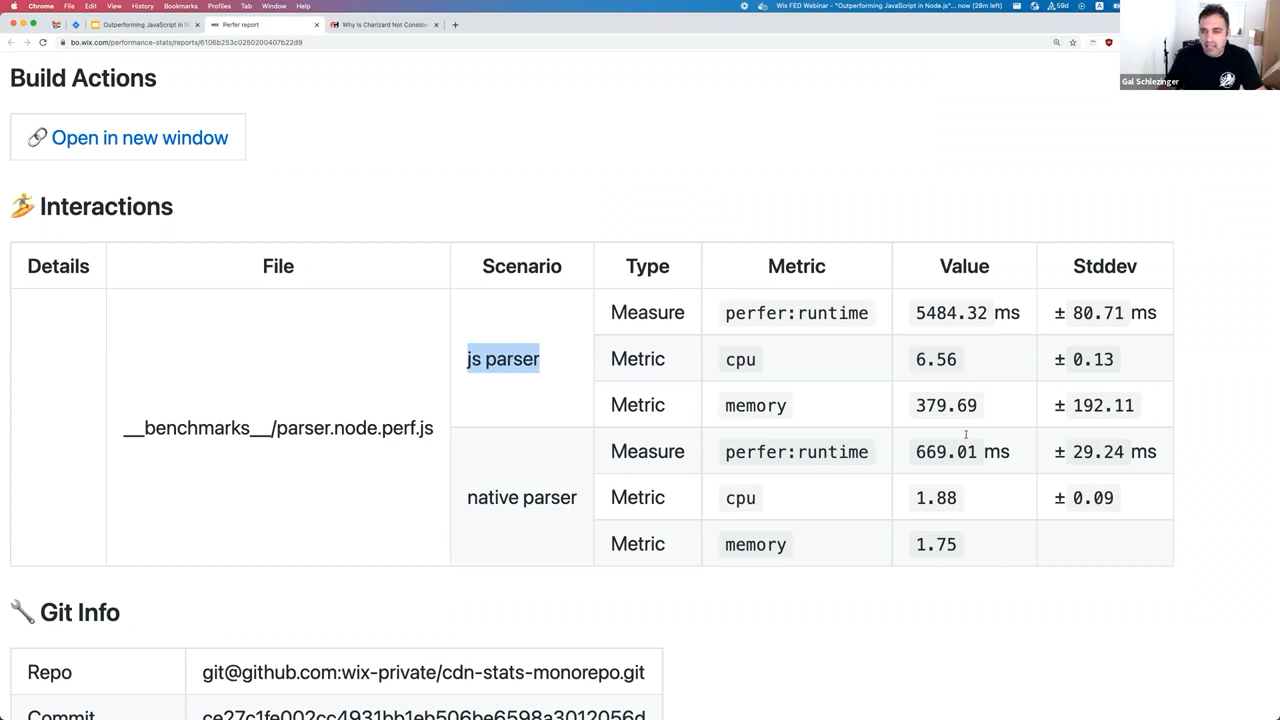 A screenshot from the web UI of the benchmarking tool
A screenshot from the web UI of the benchmarking tool
The results in plain text were as follows:
- JavaScript parser
- 5878ms of overall runtime
- 6.49sec CPU time
- 381mb of memory usage
- Rust parser
- 1145ms of overall runtime
- 3.25sec CPU time
- 1.75mb of memory usage
While there is a significant difference in times, the most glaring disparity lies in memory usage. This difference enables us to process more files in parallel. And that's a huge advantage.
Previewing a Deployment
The Wix deployment preview model is based on ephemeral Kubernetes pods that can be manually requested for a specific commit. The ingress proxy can then direct traffic to these special pods given a specific header. This is great for testing something as innovative as this project, so we decided to try running a preview deployment using the Rust parser instead of the JavaScript one.
We ran a benchmark a few times. We processed the same 190,000 log files, using the following infrastructure:
- JavaScript implementation with 25 instances, which finished in ~3 hours.
- Rust implementation with one deploy preview instance, completing in ~2.5 hours.
This does not include any database I/O (since the deploy preview instance is read-only), but:
- There are far fewer insertions in the Rust implementation because we can process more files simultaneously. This enhances our aggregation and reduces the number of records to be pushed to the database.
- We could modify our implementation to store the data directly in a simple storage like S3, and then have a separate job that transfers the data directly to the database. This would allow us to separate computational work from network work.
Assuming the times were the same, the Rust implementation used only 1/25 of the resources available to the JavaScript implementation. That's a 2500% performance boost! Even if we do need to add the MongoDB insertions, which may take some extra time, we would still be looking at a boost of 2000%? 1900%? Either way, it's a significant win.
2,500% perf boost
So, What's the Takeaway?
It seems that choosing the right tool for the job is essential. Some tasks are well-suited to JavaScript, while others are not. Although Rust is a language that's more challenging to master, we can still encapsulate the logic and distribute it in such a way that users don't mind using it. We can see this trend across the JavaScript ecosystem: Next.js replaced their use of Babel with SWC and may soon use Turbopack by default (fingers crossed). Esbuild, a popular choice for bundling and transforming TypeScript or modern JS to JavaScript, is written in Golang. It's simply faster, which is always beneficial.
So, I suppose my takeaway here is... use whatever makes you happy, and if something is too slow, profile it first, then encapsulate it, and then—perhaps—consider rewriting it in Rust. 😈
We build everything in Ruby because we love Ruby. If we need to make it super fast, we will use C.
— Zach Holman, or Tom Preston-Werner? Aahhh, I don't know! I couldn't find the sources but I do remember seeing it in a talk I watched on YouTube.